
Beaucoup datent le grand boom de l’IA générative en l’an 2023 de notre ère. Cependant, des modèles existaient déjà avant 2019, et le papier fondateur du mécanisme à l’origine du Transformer, Attention is all you need, date lui de 2017 (quasimment 10 ans)(oui, ça pique). Presque dix ans d’évolution, des centaines de modèles plus tard (peut-être plus, nous avons arrêté de compter il y a longtemps), il ne serait pas aberrant de se questionner sur l’ampleur de l’évolution des Large Language Models depuis les premiers pas.
Quels changements ont été observés depuis 2017 ? Ont-ils été majeurs ou de simple améliorations posées sur une structure très similaire ?
Les Large Language Models , ou LLMs, proposés aujourd’hui présentent-ils au final tous la même architecture ?
De plus, les dernières nouveautés affichent des performances relativement proches, malgré une course au trophée presque indécente. Cette recherche constante de puissance se retrouve t-elle dans les applications concrètes et tests auxquels ces modèles sont soumis ? A-t-on vraiment des modèles plus performants une décennie plus tard ?
Et surtout, au final, est-ce réellement de dont nous avons besoin ?
Tentons de répondre à ces nombreuses questions.
ÉVOLUTION DES MODÈLES…
Il serait bien sûr hardu et quasi-impossible de comparer tous les modèles disponibles aujourd’hui avec ce qui ce faisait avant. Afin d’illustrer notre propos, nous avons décidé de suivre l’excellent article From GPT-2 to gpt-oss: Analyzing the Architectural Advances de Sebastian Raschka, auteur du non moins excellent livre Build a Large Language Model From Scratch. Dans ce post, Raschka choisi de prendre comme exemple du passé GPT-2, un modèle LLM decoder-only, un type de modèle généralement pré-entraînés sur un vaste corpus de données, construit sur l’architecture du Transformer introduit dans le fameux papier fondateur, « Attention is all you need » (2017). Parmi les modèles récents, son attention se porte (pun intended) sur GPT-OSS et Qwen3. Pourquoi ceux-ci en particulier, demanderez-vous ? La réponse est simple : GPT OSS venait tout juste de sortir au moment de la publication, et représentait le parfait spécimen puisque également développé par OpenAI ; quant à Qwen3, GPT OSS n’ayant alors pas encore été évalué, le choix de compléter l’étude avec l’un des modèles open-source les plus plébiscités alors n’est pas incohérent.
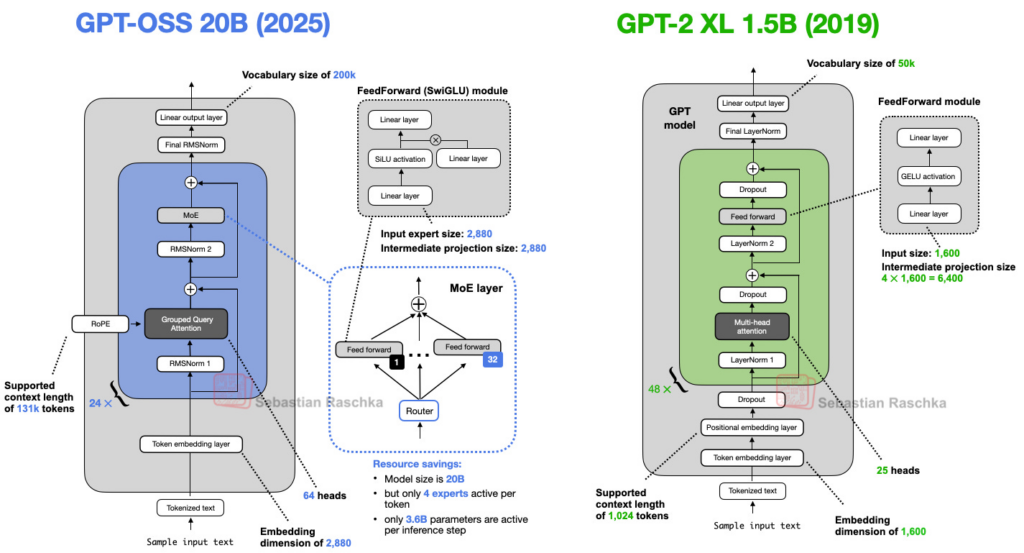
Les deux modèles côte à côte. – Sebastian Raschka, From GPT-2 to gpt-oss: Analyzing the Architectural Advances
En comparant simplement les architecture de GPT-2 et GPT-OSS, il est évident que de nombreux éléments ont évolué au fil des années. Comme le souligne Raschka, le « Dropout » a vite été abandonné après GPT-2. Le Dropout est une technique permettant de réduire l’overfitting, ou sur-entraînement, le fait de trop coller aux données d’entraînement lors de cette phase. On désactive temporairement et aléatoirement certains neurones dans le réseau, ainsi que toutes leurs connexions entrantes et sortantes. Cette procédure permet de générer des modèles légèrement différents avec des configurations de neurones différentes à chaque itération. Mais alors, pourquoi abandonner une technique permettant l’amélioration d’un modèle ? Les études tendraient à montrer que les performances des LLMs diminueraient avec l’utiliation du Dropout. En effet, les Large Language Models ne voyant chaque jeton qu’une seule fois pendant l’entraînement sur les immenses sets de données prévus à cet effet, il y aurait peu de risque d’over-fitting.
Parmi les autres différences notables, on compte également la présence de la technique RoPE, pour Rotary Position Embedding, dans Qwen3 et GPT-OSS, remplaçant l’Absolute Positional Embeddings présente dans GPT-2 : au lieu d’ajouter des informations de position en tant qu’intégrations séparées, le modèle code la position en tournant la requête et les vecteurs clés afin de dépendre de la position de chaque jeton. La notion de position et de distance entre token est alors mieux assimilée par le modèle. De plus, les fonctions d’activations, l’équivalent pour les réseaux de neurones du « potentiel d’activation » qu’on retrouve dans les neurones biologiques, semblent par ailleurs avoir évolué, passant de GELU (Gaussian Error Linear Unit) à Swish dans GPT-OSS.
L’introduction de la Mixture-of-Experts, ou MoE, est également observée, supplantant l’unique module Feed-Forward par plusieurs modules, et utilisant seulement un sous-ensemble pour chaque étape de génération de jetons. Enfin, les mécanismes d’attention paraissent avoir été modifiés : la technique de Grouped Query Attention (GQA) substitue celle de Multi-Head Attention (MHA), tandis que le masque d’attention a laissé la place à une fenêtre glissante, réduisant à la fois l’utilisation de la mémoire et les coûts de calcul.
Prise point par point, l’architecture GPT-OSS semble bien éloignée de celle de GPT-2. Mais retrouve-t-on cette évolution dans les performances comparées ?
…ET DES PERFORMANCES
Ne gardons pas le suspense plus longtemps : oui, la réponse est oui, les performances des Large Language Models ont explosées ces dernières années. Il suffit de jeter un œil au 2025 AI Index Report (déjà obsolète tant les avancées sont régulières) pour se faire une idée.
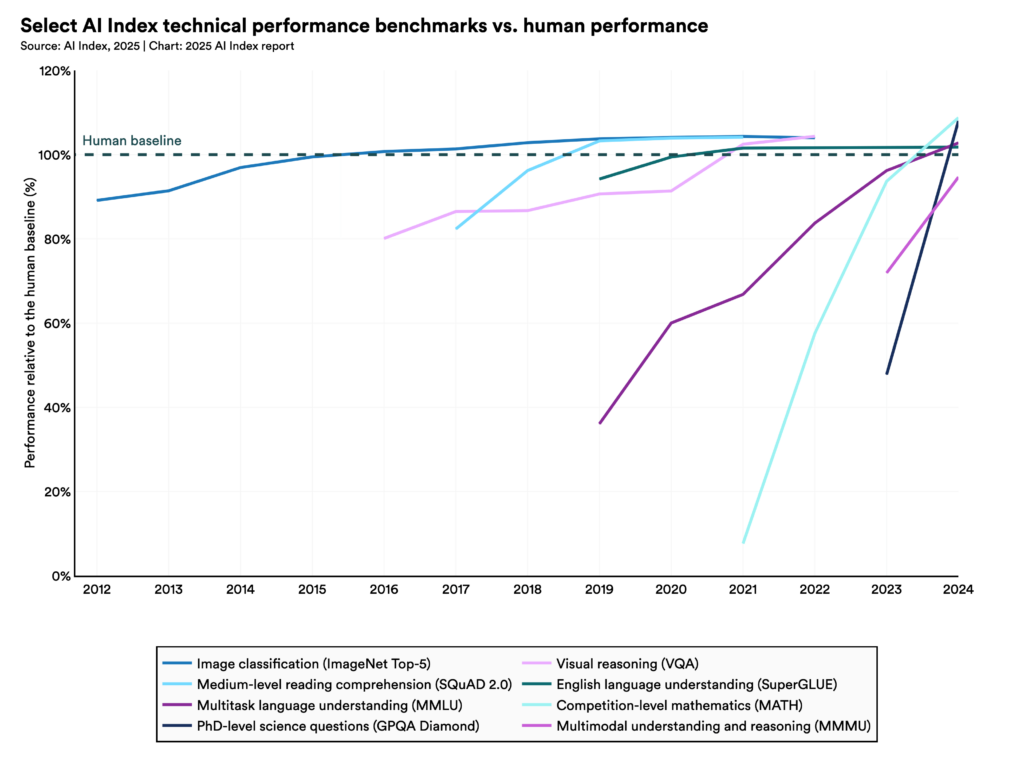
Source : 2025 AI Index Report
L’introduction de nouveaux barèmes de référence, ou benchmarks, dès 2023 a aidé à rendre compte de l’évolution en marche du côté des LLMs. Nous ne détaillerons pas ici les résultats du rapport, mais nous vous invitons fortement à y jeter un coup d’oeil. Notons tout de même que les raisonnements complexes restent un défi pour l’IA générative, mais nous reparlerons de tout ça très vite.
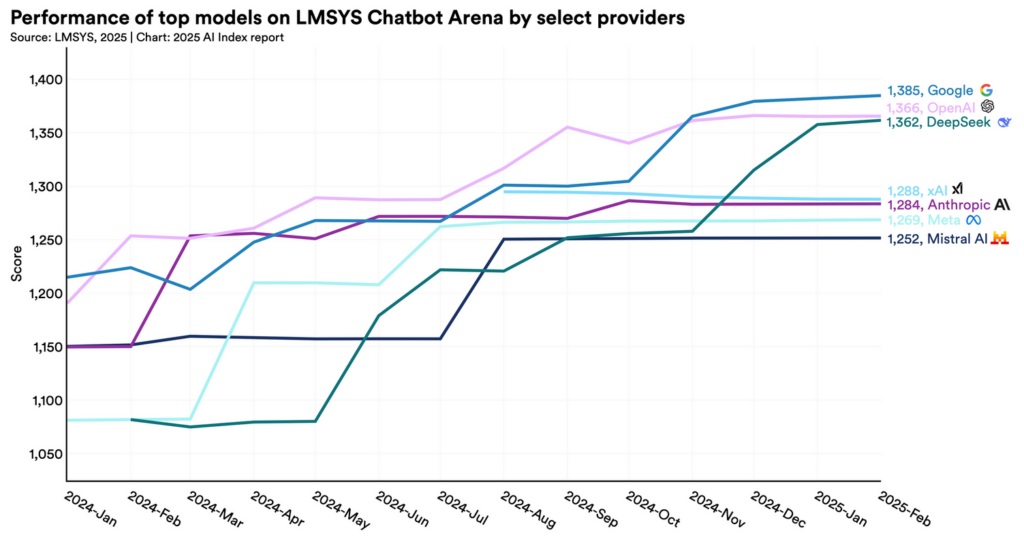
Source : 2025 AI Index Report
Une tendance intéressante se détache de tout cela : les performances de l’ensemble des modèles étudiés paraissent stagner, et l’écart entre le numéro 1 et 10 se resserre, passant de 12 % à 5,4 % en 2025. De même, l’écart de score entre numéro un et deux serait réduit à 0,7 % en 2024. Un rapport de Epoch AI prévoit une stagnation des scores de l’IA dans différentes domaines pour les prochaines années. En 2025, le marché se remplit d’offre de plus en plus performantes, le marché est plus concurrentiel que jamais, avec de nombreux modèles de haute qualité disponibles pour un nombre toujours croissant de consommateurices. Une question vient alors : existe-t-il une différence flagrante d’architecture entre tous les LLMs actuels ?
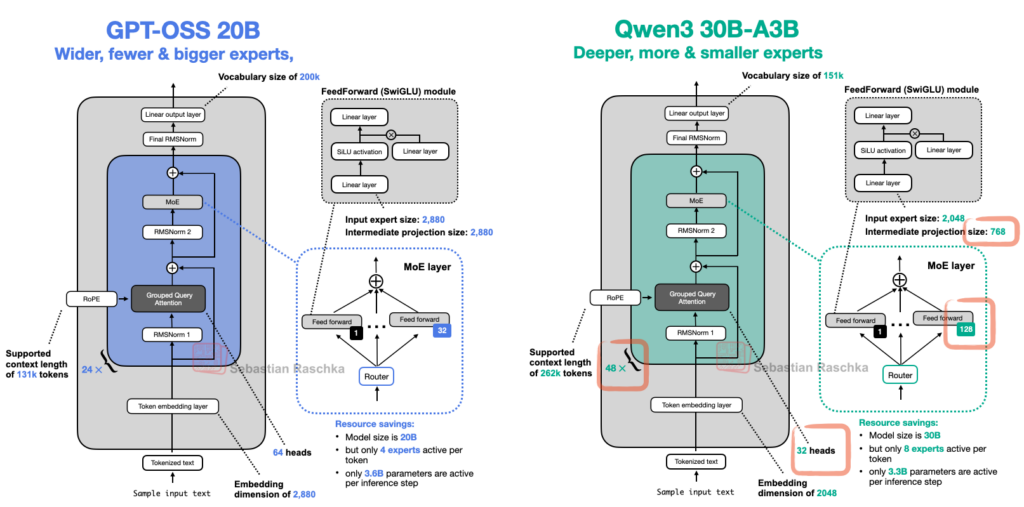
Comparaison GTP-OSS et Qwen3. – Sebastian Raschka, From GPT-2 to gpt-oss: Analyzing the Architectural Advances
Comme le souligne Raschka, l’architecture de GPT-OSS, développé par OpenAI, reste très proche de celle de Qwen3, développé par le géant Alibaba. Les deux LLMs, sortis la même années, ne présentent pas de grande différences notables et rivalisent en terme de performances.
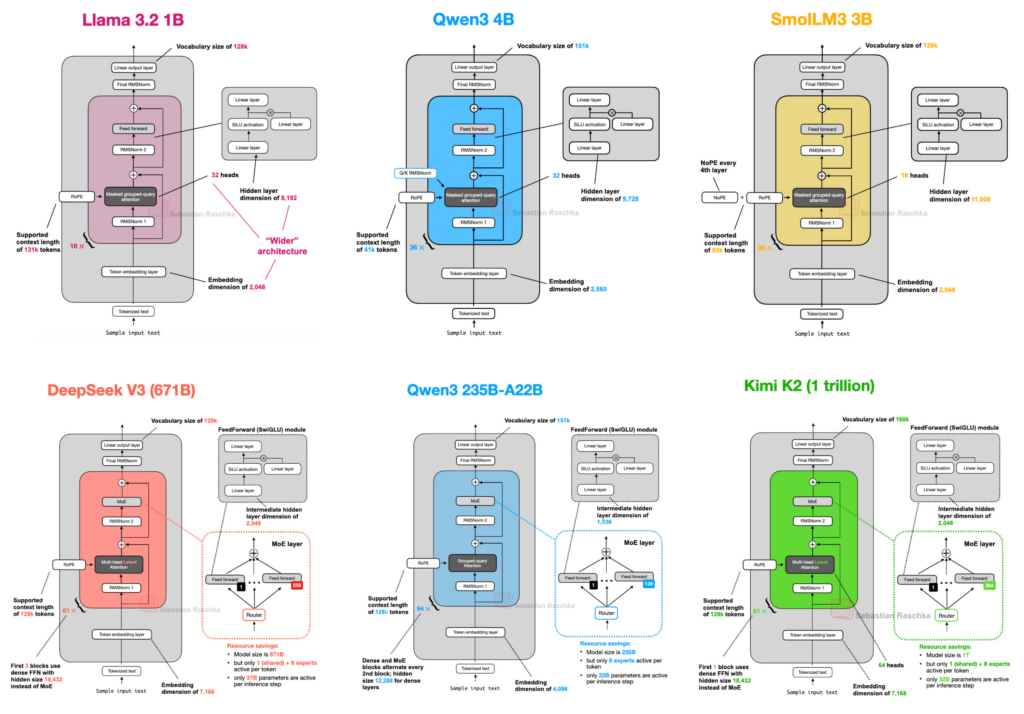
Exemples d’archietctures récentes – Sebastian Raschka, The Big LLM Architecture Comparison
En comparant les schémas de plusieurs modèles développés par différents acteurs, on pourrait s’étonner de la similitude structurelle de ces modèles. Les Large Language Models tendraient à une uniformisation des architectures, une tendance se retrouvant alors dans les performances et benchmarks. Le jeu serait alors de chercher les petites technicités propres à chacun : open-weight, open-source, moins de paramètres, méthode spécifique d’embedding… A chacun.e de trouver son LLM de coeur, pour profiter de sa puissance sans pareil. Avec de tels résultats, aucune chance d’être déçu.e, n’est-ce pas ?
N’est-ce pas ?
ATTENTION AUX BENCHMARKS
Tout scientifique le sait, évaluer est primordial dans le processus de développement. La mesure des progrès est essentielle à l’avancement de tout projet scientifique. Il est donc naturel que les tests, indices de référence et autres outils de comparaison jouent un rôle de plus en plus central dans la course à l’IA, mais deviennent aussi plus sensibles à une certaine forme de distorsion, afin de répondre au besoin de miracle de la communauté. S’extasier sur un résultat est une chose, mais l’évaluation menant à ce résultat se doit d’être aussi évaluée, afin d’assurer sa justesse ainsi que sa transparence. Mais qui évalue l’évaluation ?
Pour illustrer notre propos, nous citerons les travaux présentés dans The Leaderboard Illusion, Singh et al. – 2025. Le papier prend en exemple Chatbot Arena, devenu le leader du classement des systèmes d’IA les plus performants, et constate que ce type de test profitent à une poignée de fournisseurs d’IA génératives en mesure de tester plusieurs variantes de leur modèle avant la diffusion publique et de se retracter si les scores sont jugés trop bas. Cette divulgation sélective des performances biaise alors toute la compétition.
Il est également apparu que la proportion de modèles dits fermés (en opposition aux modèles open-weight ou open-source) sont beaucoup plus représentés dans cette compétition, menant à une asymétrie de l’accès aux données utilisées pour les tests. Les fournisseurs comme Google et OpenAI ont reçu respectivement 19,2% et 20,4% de toutes les données de l’arène. En revanche, un ensemble de 83 modèles open-weight n’a reçu que 29,7 % des données totales. Les modèles fermés tendraient alors à l’over-fitting sur les tests tels que Chatbot Arena, offrant alors des performances plus importantes que ceux ne présentant pas cet avantage.
Avant de crier au génie devant les chiffres, il serait bon de s’assurer que l’on peut se fier aux évaluations proposées.
MAIS DANS QUEL BUT ?
Avant de conclure, rappelons qu’il apparaît évident que les progrès croissant (mais peut-être plus pour longtemps) des LLM s’accompagne de leur augmentation continue de demande en ressource de calcul, que ce soit pour la phase d’entraînement ou la mise en fonctionnement. Si cette tendance se poursuit jusqu’en 2030, il est facile d’imaginer un scénario de référence sur l’IA, ses besoins et ses effets concrets. En effet, pour maintenir ce rythme jusqu’en 2030, sans crises majeures, les demandes en capital, données,capacité électrique et fabrication de puces seront toujours plus grandes. Selon le rapport What will AI look like in 2030 ?, la puissance utilisée au pic par les plus gros entraînements doublerait environ tous les 8–9 mois. Puisque les entraînements dureraient de plus en plus longtemps, l’énergie totale consommée augmenterait encore plus vite. Si la trajectoire se prolonge, l’IA pourrait mobiliser autour de 1 % de l’électricité mondiale d’ici à 2030.
Au final, les performances affichées des Large Language Models les plus en vus sont-elles réellement un élément à mettre en avant dans un monde en feu ? Si les progrès continus des performances, progrès pouvant être remis en question tant les tests utilisés manquent souvent de transparence et d’équité, s’accompagnent d’une augmentation importante des demandes en ressources diverses, est-il au final pertinent et aligné avec l’avenir que beaucoup essayent de construire de poursuivre cette course sans fin ?
Nous n’en sommes pas convaincu.e.s.
Laisser un commentaire